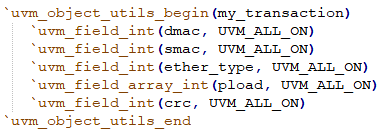
2. config_db机制
2.1 介绍
用来传递参数,一般有以下三种应用场景:
(1)传递virtual interface到环境中。
(2)设置单一变量值,例如int、string、enum等。
(3)传递配置对象到环境。
2.2 用法
set函数是寄信,而get函数是收信。如在某个测试用例的build_phase中可以使用如下方式寄信:
uvm_config_db#(int)::set(this,"env.i_agt.drv","pre_num",100);
其中第一个和第二个参数联合起来组成目标路径,与此路径符合的目标才能收信。第一个参数必须是一个uvm_component实例的指针,第二个参数是相对此实例的路径。第三个参数表示一个记号,用以说明这个值是传给目标中的哪个成员的,第四个参数是要设置的值。
在driver中的build_phase使用如下方式收信:
uvm_config_db#(int)::get(this,"","pre num",pre num);
get函数中的第一个参数和第二个参数联合起来组成路径。第一个参数也必须是一个uvm_component实例的指针,第二个参数是相对此实例的路径。一般的,如果第一个参数被设置为this,那么第二个参数可以是一个空的字符串。第三个参数就是set函数中的第三个参数,这两个参数必须严格匹配,第四个参数则是要设置的变量。
2.3 使用实例
2.3.1 interface传递
在实现接口传递的过程中需要注意:
(1)在传递过程中的类型应当为virtual interface,即实际接口的句柄。
(2)接口传递应该发生在run_test()之前。这保证了在进入build phase之前,virtual interface已经被传递到uvm_config_db中。
interface intf1;
logic enable=0;
endinterface
class compl extends uvm component;
`uvm_component_utils(comp1)
virtual intf1 vif;
function void build_phase(uvm phase phase);
if(!uvm config db#(virtual intf1):: get(this,"","vif", vif)) begin
uvm_error("GETVIF","no virtual interface is assigned")
end
`uvm_info("SETVAL",$sformatf("vif. enable is %b before set", vif. enable), UVM LOW)
vif.enable=1;
`uvm info("SETVAL",$sformatf("vif. enable is b after set", vif. enable), UVM LOW)
endfunction
endclass
class testl extends uvm_test;
`uvm_component_utils(test1)
comp1(c1)
endclass
intf1 intf();
initial begin
uvm_config_db#(virtual intf1)::set(uvm root::get(),"uvm test top. cl","vif", intf);
run test("test1");
end
//输出结果:
UVM_INFO @ 0:reporter [RNTST] Running test test1...
UVM_INFO @ 0:uvm_test_top.cl [SETVAL] vif.enable is 0 before set
UVM_INFO @ 0:uvm_test_top.cl [SETVAL] vif.enable is 1 after set
2.3.2 变量传递
在各个test中, 可以在build phase对底层组件的变量加以配置, 进而在环境例化之前完成配置, 使得环境可以按照预期运行。
代码与2.3.1类似。
2.3.3 object传递
在test配置中,需要配置的参数不只是数量多,而且可能还分属于不同的组件,如果每个变量单独传递,容易出错,还不能复用。因此我们可以将每个组件中的变量加以整合,首先放置到一个uvm_object中,再对中心化的配置对象进行传递,会更有利于整体环境的修改维护。
class configl extends uvm object;
int val1=1;
int str1="null";
uvm_object_uti1s(config1)
...
endclass
class comp1 extends uvm_component;
`uvm_component_uti1s(comp1)
configl cfg;
...
function void build_phase(uvm phase phase);
uvm_object_tmp;
uvm_config_db#(uvm_object):: get(this,"","cfg", tmp);
void'($cast(cfg, tmp));
uvm_info("SETVAL",$sformatf("cfg.vall is %d after get", cfg. val1), UVM_LOW)
uvm_info("SETVAL",$sformatf("cfg.str1 is %s after get", cfg. str1), UVM_LOW)
endfunction
endclass
class test1 extends uvm_test;
`uvm component utils(test1)
comp1 c1,c2;
config1 cfgl,cfg2;
...
function void build_phase(uvm_phase phase);
cfg1=config1::type id::create("cfg1");
cfg2=configl::type_id::create("cfg2");
cfg1.val1=30;
Cfg1.strl="c1";
Cfg2.val1=50;
cfg2.strl="c2";
uvm_config_db#(uvm_object):set(this,"cl","cfg", cfg1);
uvm_config_db#(uvm object):set(this,"c2","cfg", cfg2);
c1=comp1::type id::create("c1", this);
c2=comp1::type_id::create("c2", this);
endfunction
endclass